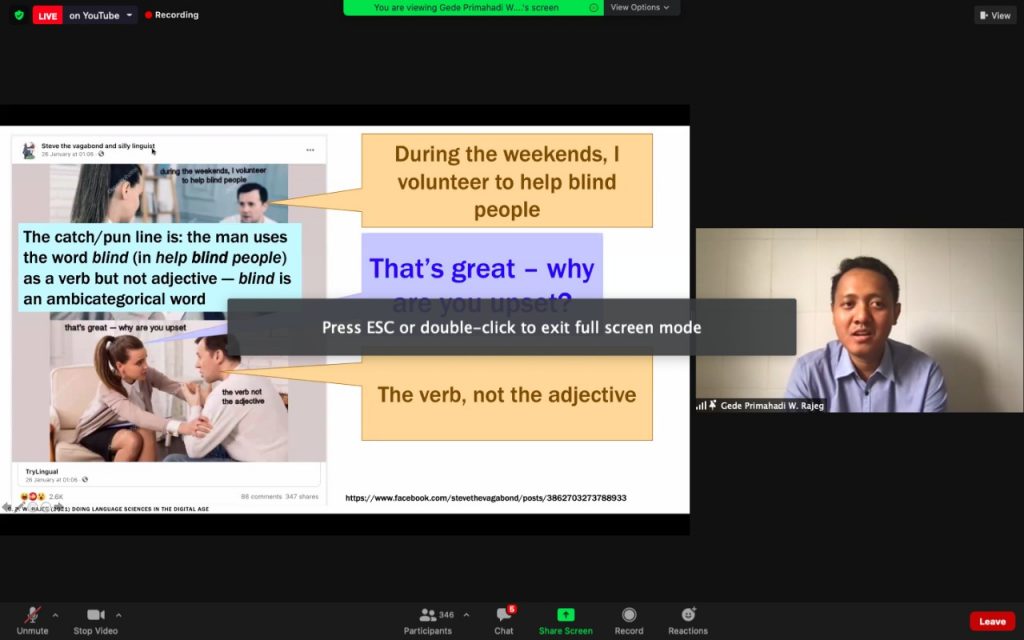
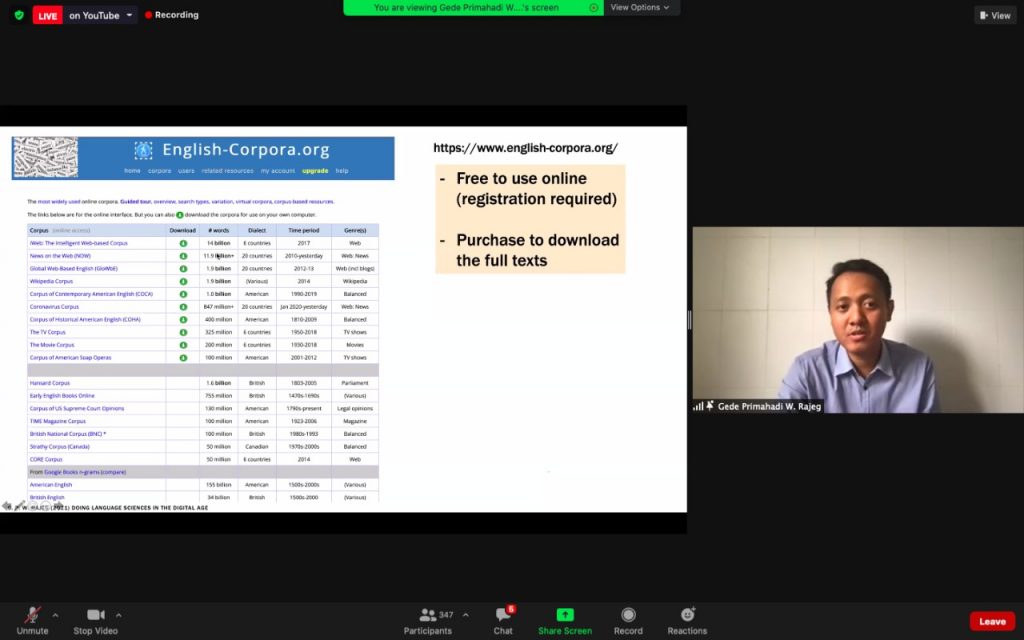
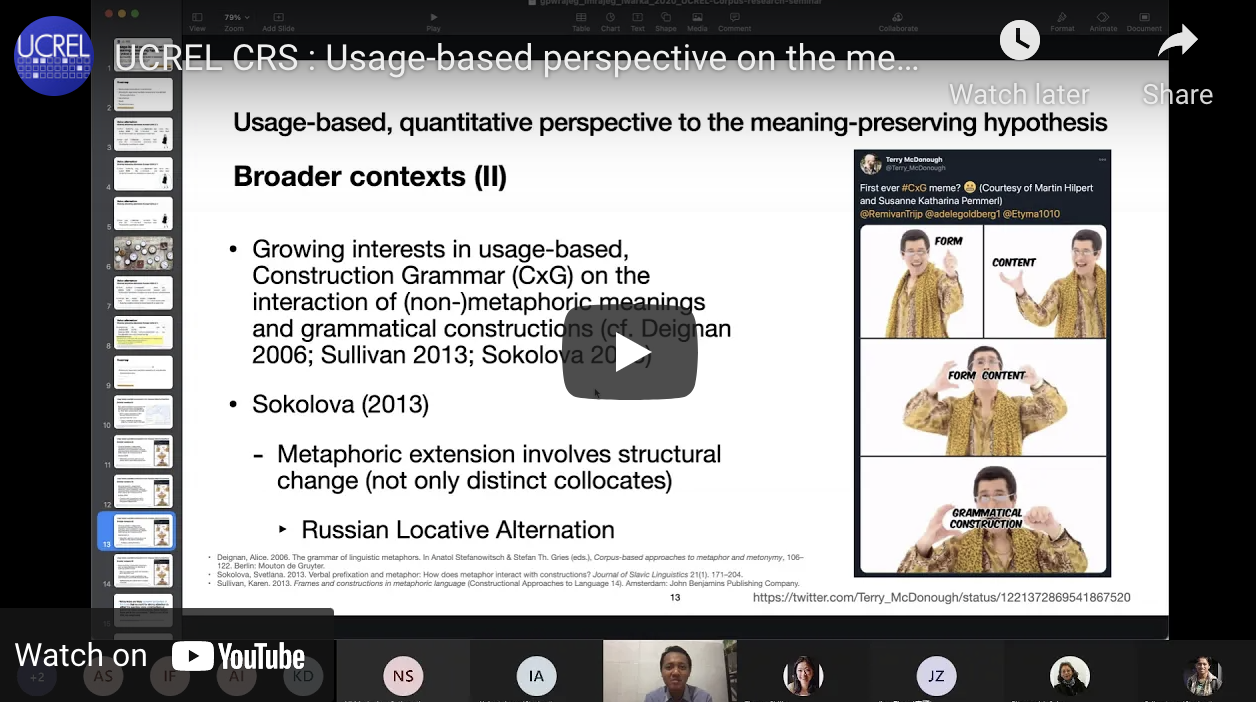
A paper by Gede Primahadi Wijaya Rajeg, I Made Rajeg, and I Wayan Arka has just been published in the LFG’20 Proceedings. The title of the paper is Corpus-based approach meets LFG: the puzzling case of voice alternations of kena-verbs in Indonesian.
Rajeg, Gede Primahadi Wijaya, I Made Rajeg & I Wayan Arka. 2020. Corpus-based approach meets LFG: the puzzling case of voice alternations of kena-verbs in Indonesian. In Miriam Butt & Ida Toivonen (eds.), Proceedings of the LFG’20 conference, on-line, 307–327. Stanford, CA: CSLI Publications. http://cslipublications.stanford.edu/LFG/2020/lfg2020-rra.pdf.
Rajeg, G. P. W., Rajeg, I. M., & Arka, I. W. (2021, May 10). Supplementary materials for “Corpus-based approach meets LFG: Puzzling voice alternation in Indonesian.” https://doi.org/10.17605/OSF.IO/YMD2V